시크릿은 비밀번호, OAuth 토큰, SSH 키와 같은 민감한 정보들을 저장하는 용도로 사용한다. 이러한 정보들은 컨테이너 안에 저장하지 않고 별도로 보관했다가 실제 파드를 실행할 때의 템플릿으로 컨테이너에 제공한다.
시크릿은 내장 시크릿과 사용자 정의 시크릿이 있다. 내장 시크릿은 쿠버네트 클러스터 안에서 쿠버네티스 API에 접근할 때 사용한다.
클러스터 안에서 사용하는 ServiceAccount라는 계정을 생성하면 자동으로 관련 시크릿을 만든다. 이 시크릿으로 ServiceAccount가 사용 권한을 갖는 API에 접근할 수 있다. 사용자 정의 시크릿은 사용자가 만든 시크릿이다.
시크릿은 kubectl create secret 명령으로 만들 수 있고 다른 자원처럼 템플릿으로 만들 수 있다.
시크릿 생성
echo -n 명령으로 사용자 이름과 비밀번호를 설정하는 파일을 생성한다.

이후 kubectl create secret generic 시크릿이름 명령으로 user-pass-secret이라는 시크릿을 만든다.

$ kubectl get secret 시크릿이름 -o yaml #생성한 시크릿 확인 가능

.data 필드의 하위 필드로 .password.txt / .username.txt 라는 파일이 있는 것을 확인할 수 있다. 필드 값은 지정한 문구 그대로가 아닌 base64 문자 인코딩 방식이다. 시크릿이 생성될 때 자동으로 필드 값을 base64로 인코딩한 것이다.
다음 명령어로 필드 값들을 디코딩 할 수 있다.

템플릿으로 시크릿 만들기

.type 필드 값으로 Opaque인 것을 확인할 수 있다.
| 시크릿 타입 | 설명 |
| Opaque | 기본 값. 키-값 형식으로 임의의 데이터를 설정할 수 있다. |
| kubernetes.io/service-account-token | 쿠버네티스 인증 토큰을 저장 |
| kubernetes.io/dockercfg | 도커 저장소 환경 설정 정보를 저장 |
| kubernetes.io/dockerconfigjson | 도커 저장소 인증 정보를 저장 |
| kubernetes.io/basic-auth | 기본 인증을 위한 자격 증명 저장 |
| kubernetes.io/ssh-auth | SSH 접속을 위한 자격 증명 저장 |
| kubernetes.io/tls | TLS 인증서 저장 |
| bootstrap.kubernetes.io/token | 부트스트랩 토큰 데이터 정보를 저장 |
시크릿 사용
시크릿은 파드의 환경 변수나 볼륨을 이용한 파일 형식으로 사용할 수 있다.

.spec.template.spec.containers[ ].env[ ] 필드를 확인했을 때
첫 번째 .name 필드 값으로는 SECRET_USERNAME이라는 환경 변수 이름을 설정했고 하위의 .valueFrom 필드에 .secretKeyRef .name과 .key라는 하위 필드를 설정해 시크릿의 이름(user-pass-yaml)과 키 값(username)을 참조한다.
두 번째 .name 필드 값으로는 SECRET_PASSWORD라는 환경 변수 이름을 설정해 .secretKeyRef.name과 .key라는 하위 필드를 설정해 시크릿의 이름과 키 값을 참조한다.
이후 kubectl apply -f deployment-secret01.yaml 명령을 실행해 클러스터에 적용한다.
그리고 웹 브라우저에서 localhost:30900/env 에 접속 해준다.
파드에서 불러온 시크릿 설정(SECRET_USERNAME=username & SECRET_PASSWORD=password)을 확인할 수 있다.

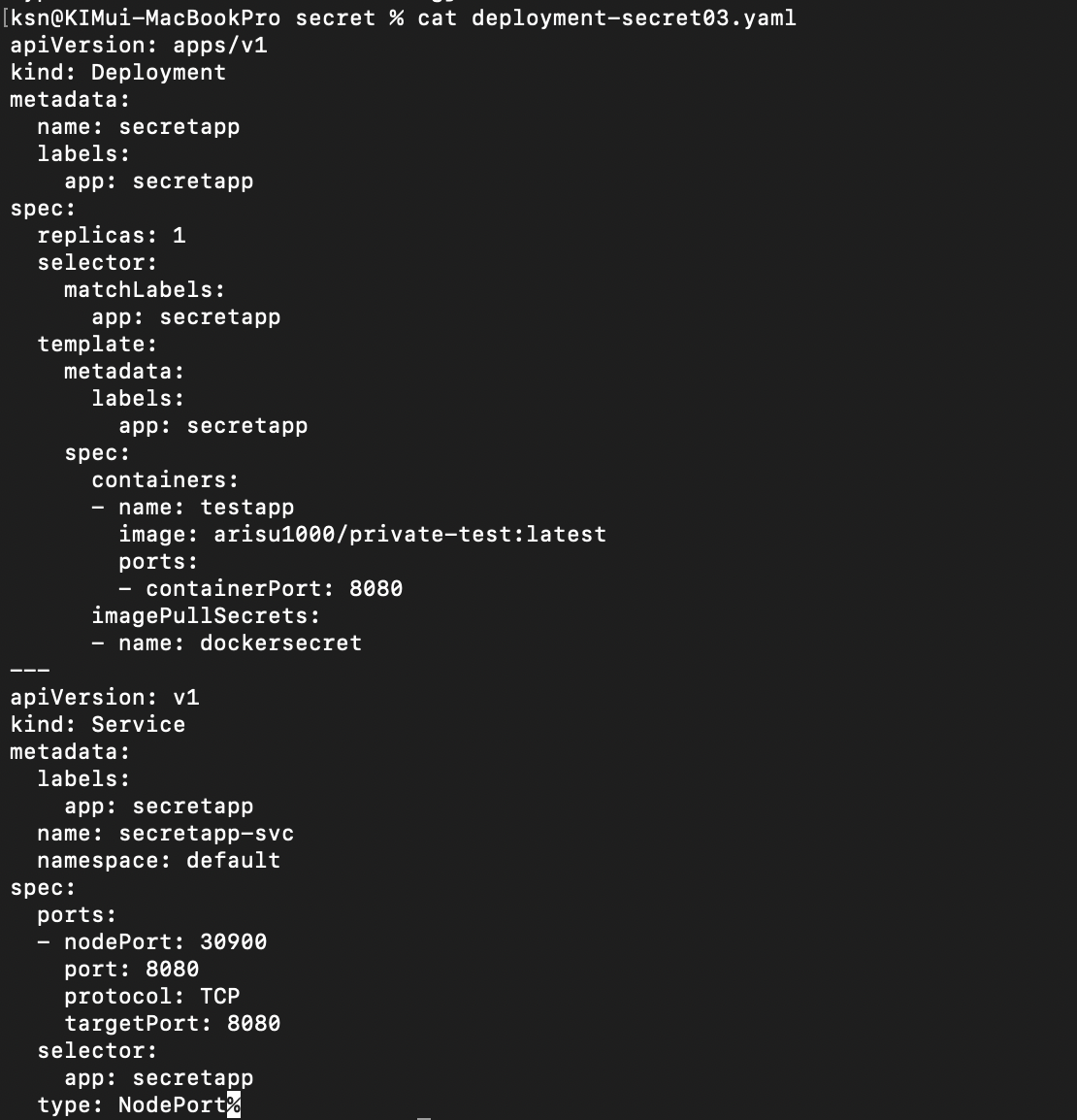
프라이빗 컨테이너 이미지를 가져올 때 시크릿 사용
보통 컨테이너에서 이미지를 pull 할 때는 대부분 공개된 이미지를 사용한다. 프라이빗 컨테이너 이미지를 사용하려면 인증 정보가 필요하다. 로컬 서버라면 프라이빗 컨테이너 이미지 사용 권한(인증 정보)를 저장한 후 사용할 수 있지만 쿠버네티스 클러스터에서는 보안상의 위험이 있으므로 그렇게 설정하지 않는다. 인증 정보를 시크릿에 설정해 저장한 후 사용한다.
쿠버네티스에는 kubectl create secret의 하위 명령으로 도커 컨테이너 이미지 저장소용 시크릿을 만드는 docker-registry가 있다.

위와 같이 시크릿을 생성해준 뒤 어떻게 사용하는지 확인해준다.
기존과는 다르게 .data 필드 아래 .dockerconfigjson라는 필드와 앞에서 설정한 도커 인증 정보 값이 설정돼있다.
*.type 필드 값은 kubernetes.io/dockerconfigjson(도커 저장소 인증 정보를 저장)이다.
<출처>
정원천 외 3명, 쿠버네티스 입문 90가지 예제로 배우는 컨테이너 관리 자동화 표준
'DevOps > KUBERNETES' 카테고리의 다른 글
| [8] 컨피그맵(configmap) (0) | 2024.05.02 |
|---|---|
| [7] 서비스(Services) (0) | 2024.04.29 |
| [6-2] 컨트롤러(Controller) - 디플로이먼트 (1) | 2024.04.26 |
| [6-1] 컨트롤러(Controller)- 레플리케이션 컨트롤러, 레플리카세트 (1) | 2024.04.25 |
| [5] 파드(Pod) -2 (1) | 2024.04.23 |